June 10, 2014
Summary: If your functions return core.async channels instead of taking callbacks, you encourage them to be called within go blocks. Unchecked, this encouragement could proliferate your use of go blocks unnecessarily. There are some coding conventions that can minimize this problem.
I've been using (and enjoying!) core.async for about a year now (mostly in ClojureScript). It has been a huge help for easily building concurrency patterns that would be incredibly difficult to engineer (and maintain and change) without it.
Over that year, I've developed some practices for writing code with core.async. I'm putting them here as an invitation for discussion.
Use callback style, if possible
A style develops when using core.async where you convert what would in regular ClojureScript be a callback style with return-a-channel style. The channel will contain the result of the call when it is ready.
Using this style to keep you out of "callback hell" is overkill. "Callback hell" is not caused by a single callback. It is caused by the eternal damnation of coordinating multiple callbacks when they could be called in any order at any time. Callbacks invert control.
core.async quenches the hellfire because coordinating channels within a go block is easy. The go block decides which values to read in which order. Control is restored to the code in a procedural style.
But return-a-channel style is not exactly free of sin. If you return a channel too much, the code that calls those functions will likely end up in a go block.
go blocks will proliferate. go blocks incur extra cost, especially in ClojureScript where they happen asynchronously, meaning at the next iteration of the event loop, which is indeterminately far away.
Furthermore, go blocks might begin nesting (a function whose body is a go block is called by another function whose body is a go block, etc), which is correct semantically but probably won't give you the performance you're looking for. It's best to avoid it.
"How?" you say? The most important rule is to only use core.async in a particular function when necessary. If you can get by with just a callback, don't use core.async. Just use a callback. For instance, let's say you have an ajax function that takes a callback and you're trying to make a small API wrapper for convenience. You could make it return a channel like this:
(defn search-google [query]
(let [c (chan)]
(ajax (str "http://google.com/?q=" query) #(put! c %))
c))
The interesting thing to note is that core.async is not being used very well above. Yes, you get rid of a callback, but there isn't much coordination happening, so it's not needed. It's best to keep it straightforward, like this:
(defn search-google [query cb]
(ajax (str "http://gooogle.com/?q=" query) cb))
You're just doing one bit of work here (basically constructing a URL), which is a good sign. But how do you "lift" this into core.async?
<<<
There's a common pattern in Javascript (not ubiquitous, but very common) to put the callback at the end of the parameter list. Since the callback is last, you can easily write something to add it automatically.
(defn <<< [f & args]
(let [c (chan)]
(apply f (concat args [(fn [x]
(if (or (nil? x)
(undefined? x))
(close! c)
(put! c x)))]))
c))
This little function is very handy. It automatically adds a callback to a parameter list. You call it like this:
(go
(js/console.log (<! (<<< search-google "unicorn droppings"))))
This function lifts search-google, a regular asynchronous function written with callback style, into core.async return-a-channel style. With this function, if I always put the callback at the end, I can use my functions from within regular ClojureScript code and also from core.async code. I can also use any function (and there are many) that happen to have the callback last. This convention has two parts: always put the callback last and use <<< when you need it. With this function, I can reserve core.async for coordination (what it's good at), not merely simple asynchrony.
<convention
There are times when writing a function using go blocks and returning channels is the best way. In those cases, I've adopted a naming convention. I put a < prefix in front of functions that return channels. I tried it at the end of the name, but I like how it looks at the beginning.
(go
(js/console.log (<! (<do-something 1 2 3))))
The left-arrow of <do-something fits right into the <!. It also visually matches (<<< do-something 1 2 3), so it makes correct code look correct and wrong code look wrong. The naming convention extends to named values as well:
(def <values (chan))
(go
(while true
(js/console.log (inc (<! <values)))))
Conclusion
These conventions are a great compromise between ease of using core.async (<<<) and universality (callbacks being universal in JS). The naming convention (< prefix) visually marks code that should be used with core.async. These practices have taken me a long way. I'd love to discuss them with you here.
If you know Clojure and you are interested in learning core.async in a fun, interactive style, check out the LispCast Clojure core.async videos.
You might also like
November 13, 2014
A true history
Summary: Conveyor belts are strikingly similar to Clojure core.async channels. While it could be a coincidence, there is speculation that conveyor belts were influenced by a deep understanding of core.async.
Who invented the conveyor belt? No one knows for sure. Many historians believe that it was Henry Ford, seeking to mechanize the transportation of car parts from one part of the factory to another. This conservative view is plausible. Henry Ford designed much of the assembly line in his factories.
Despite the simplicity of this explanation, a small minority of researchers believe that there was a man behind Henry Ford who was the true inventor of the conveyor belt. Not much is known about him, but historians have pieced together a different story. This article is about that story.
This is a classic picture of Henry Ford standing in front of his creation. Recent advances in digital imaging enhancement have allowed us to learn a little more about the people that influenced Ford who, until recently, have lived within his shadow.
While the identity of this man is not known, historians have reassembled a story from bits and pieces of Henry Ford's journals and quotes. It is believed (by those few, brave historians) that this man is the true inventor of the conveyor belt. He looks eerily similar to the famed inventor of Clojure, Rich Hickey. However, the chronologies do not match up, so this hypothesis is easily ruled out.
Conveyor belt similarities to core.async channels
It is well understood that the conveyor belt is a poor, physical compromise on the much more reasonable abstraction of the Clojure core.async channel. As lossy as the copy is, it is still quite useful. core.async channels and conveyor belts have many properties in common.
Things can be put onto and taken off of a conveyor belt
The similarity here is uncanny. It is almost as if the inventor of the conveyor belt had some knowledge of the core.async operations.
The conveyor belt serves as a buffer
Again, it is striking that the conveyor belt can serve nearly the same purpose as a core.async channel. On long conveyor belts, the people taking things off and putting things on might not even know each other. And for things that take an unknown amount of time, you can just point to the conveyor belt and say "Wait here for the thing you need." They don't have to know when or from where it is coming.
Things can be taken off in the same order they are put on
This is something that perhaps the conveyor belt has lost. While core.async channels always maintain their own semantics for choosing which thing is taken next, conveyor belts are basically dumb and expose all of their contents. However, it is clear that you could enforce the common "first-in-first-out" queue behavior by always taking the last item from a conveyor belt.
When the conveyor belt is full, the "putter" has to wait
What happens when the conveyor belt fills up? Well, you wait for some room. Everyone has had this experience where you're at the supermarket and the cashier is taking too long to ring up your food so the conveyor belt fills up. You just have to wait with a dumb look while they look up the code for celery.
When the conveyor belt is empty, the "taker" waits
Conversely to the full belt situation, when the belt is empty the taker must wait. This is what happens when the cashier is faster than the shopper at the supermarket. There's nothing to do but wait for some groceries to reach the end of the belt.
Differences between conveyor belts and core.async channels
Though the evidence that core.async influenced the development of the conveyor belt is overwhelming, there are some differences due to the physical limitations of time and space.
Non-instantaneous transfer
Though not truly instantaneous, core.async channels do operate at the speed of light. When a value is put onto a channel, it is immediately available to be taken. Contrast this with conveyor belts, which slowly move objects along a physical belt.
Limited in length
Conveyor belts have finite length. But core.async channels can be passed around just like any other object. They, in fact, are not limited by space at all. Also, the length of a conveyor belt is equivalent to its size as a buffer. But core.async channels have properly decomplected buffer size from "distance" of travel.
No dropping/sliding semantics
It is quite curious that this important feature of core.async channels has not been copied to conveyor belts. core.async channels can be set up to drop either the newest value added or the oldest value added. Conveyor belts that do that are considered defective. The best explanation is that physical goods are so expensive compared to computing ephemeral values that it is uneconomical to trow away any items after they are made.
The jury is still out as to whether core.async influenced the development of conveyor belts. Was Tony Hoare, who invented Communicating Sequential Processes (on which core.async is based) given the secret to CSP by this same man? This hypothesis becomes more convincing when we see the immense similarities between conveyor belts and core.async channels.
Here is a picture of Rich Hickey being picked up by a friend after Strange Loop 2014.
If you would like to explore the mysteries of the strange and tangled similarities between conveyor belts and core.async, you might want to try LispCast Clojure core.async. It's a video series that introduces the concepts using animations, code, and exercises.
You might also like
February 27, 2015
Summary: If something is important, you should deal with it sooner and more often. That's the approach Clojure takes to data representations. It means serialization of internal data is a non-issue.
Netflix has a counterintuitive but brilliant system called Chaos Monkey. Chaos Monkey will randomly kill services. It is trying to simulate, in the microcosm of a business day, the craziness that happens in the production macrocosm. Services die, servers fail, latency spikes, and networks partition. It might not be soon, but eventually it will happen. Better deal with it now, when people are at work to deal with it. Chaos Monkey encourages you to write your code to work in such a chaos-filled environment so that unexpected failures are a breeze. The idea is an instance of the more general principle of "if something is important, deal with it sooner and more often".
There's something related to this idea of surfacing the errors early that I've been thinking about. It's about data. Have you ever written some classes and everything is well and good. And then after a while, you need to serialize that to disk or across a network. Now you have to come up with some format (maybe JSON or XML) to represent your class. Then, whenever the class changes, you have to remember to change the data format to keep them in sync. It's kind of painful!
Well, I'll tell you, that rarely happens in Clojure. Because in Clojure, you often start with data structures. Meaning, you're already thinking in data, modeling in data, and working in data. Serialization becomes a non-issue, because Clojure data structures come built in with readers and writers. Just like causing errors to happen early because they will happen eventually, Clojure programmers code in data in part because you're going to need data (serialization and deserialization) eventually.
If this idea intrigues you, you may want to check out Clojure. Its data structures are cutting edge! Check out LispCast Introduction to Clojure if you would like to get into functional programming using animations, exercises, and screencasts.
You might also like
December 23, 2014
Summary: "Prefer data over functions" is a common adage in Clojure circles. It is poorly debated because it is a terse statement in generalities. A valuable perspective is that data is transparent at runtime, while functions are not. This perspective gives a firm ground for discussion and design.
There's a design rule of thumb in Clojure that says that we should prefer functions to macros and to prefer data to functions. People talk about why, people react saying that functions are data, etc. It's all true, but it's all missing the point. It doesn't get at the fundamental, structural difference. And I think the discussion breaks down because people speak in generalities and not much is made measurable and concrete. But the pregression from macros to functions to data is, in my opinion, increasing in one important aspect, and that's the availability at runtime. Discussions should hinge on whether availability at runtime is desirable, which of course needs to be determined on a case-by-case basis.
Macros
Macros in Clojure are simply not available at runtime. By definition, they are expanded at compile time. It would be hard to make sense to be passing around macros as runtime values. Try to pass a macro as an argument to a function. You can't.
Further, once a macro has been expanded, it is no longer clear that it's expanded code even came from that macro. Macros are opaque at runtime.
Functions
Functions are first-class values. They can be passed around to functions, stored in maps, etc. They are totally available at runtime to be called.
But, calling them is about all you can do with them (besides building new functions with them, like with composition). You can't even easily inspect the code that's inside them, nor get at the environment they have closed over. And that's kind of the point. The function is a useful unit of computation. It's not a unit of semantics.
A function, too, is opaque in its way. A function, at runtime, is a black box. What does it do? You can't tell. You can't even tell how the function got there. Was it a fn defined in code? Or was it the result of function composition using comp? That information is not available at runtime.
Data
In Clojure, by data, people are really talking about the immutable data structures available in Clojure. Just to be concrete, let's narrow the definition of Clojure data down to edn.
Edn data is available at runtime. It's first-class in the way that functions are and macros are not. But it is also transparent. The structure of the data is completely available at runtime, unlike the structure of the function. This is why data is preferable.
Because data is available at runtime, you can do many things with it. Does the data describe a computation? Well, write an interpreter. Interpreters are much easier to write than compilers (macros) because the interpreter runs at runtime in the dynamic environment of the program. Compilers (and macros) separate out the two phases of compile-time and runtime. You have to keep track of the difference in your code. And Lisp is totally well-suited for writing interpreters. The first Lisp was defined in itself, for crying out loud.
And since it's just edn, it can also be manipulated using all of the tools available in the language. Maps can be assoced to. Sequences can be iterated. Transfering it over the wire is easy. Storing it to disk in a way that can be read in is easy. Try pretty-printing a function. But pretty-printing a data structure? Easy.
And, finally, the other thing about data is that it can be interpreted in different ways by different interpreters. I'm not trying to say that you might implement two algorithms for doing the same thing. What I'm getting at is that you can compute from it, or analyze it, or algebraically transform it, etc. It has become a semantic system in its own right.
Discussion
Why not work with code, which is data in Clojure?
You can argue that since code is data, why should I use data structures likes maps and vectors instead of actual code, represented as lists? This is actually a very valid point, and I think this is one of the better arguments. Lisp was defined in terms of an interpreter for data structures which together provide a powerful programming model. It would be foolish to discard this power and define our own for no reason.
The best reason I can think of is that our data is usually a very restricted form of code, many times not Turing complete. Turing complete code is proven to be impossible to analyze. But our restricted data model is powerful in exactly the way we need it (for our specific problem), but not generally powerful (as in Turing complete). So we can design it to be analyzable.
If we can restrict the power to be less-than-Turing-complete, we can analyze it at runtime. If analyzing it at runtime is desirable, then it is desirable to represent it as data.
The semantics of data is vague, while code is well-defined. Why should we use data instead of code?
Ok, this is also a good point. Clojure code, in theory, is well defined. At the very least, it is defined as whatever the compiler does. Most of the time, it is well-documented and well-understood. But your ad-hoc data structure, which represents some computation, has all sorts of assumptions baked in, like what keys are valid when, that are undocumented, have poor error messages, and maybe corner cases.
Wow, such a good point. When you're designing a DSL, this is always a challenge. But, just like restricting your power to below Turing complete can make your analysis way easier, keeping your semantic model simple and well-defined is the key to making it worthwhile. If the semantic model is simple, it could be beneficial to have it available at runtime. For instance, you could create a custom editor for it. If it's just functions, that's out.
Hasn't this discussion happened many times before? I mean, Ant started off ok, but then it was its own programming language and it sucked.
This is very true. People have talked before about the difference between internal and external DSLs, and how external DSLs eventually lose because they need all sorts of conditionals and loops, which the internal DSLs had by default. In my experience, this is true.
My personal guideline is that I only prefer data after I have bound the problem to a well-understood domain. That means that I have to write the program first in code, using functions, before I realize that, yes, this could be described very succinctly and declaratively as data. This took a long time and lots of mistakes to understand. I essentially will only refactor to a data-driven approach after I already have it written and working.
Conclusions
I've been coding in Lisp for a long time, so I've internalized this idea of data-driven programming. It's the main idea of Paradigms of Artificial Intelligence Programming, one of the best Lisp books out there, and a big influence on me. What the guideline of "Prefer data over functions" means to me is that when it's beneficial, one should choose data, even if functions are easy to write. Data is more flexible and more available at runtime. It's one of those all-things-being-equal situations. But all things are rarely equal. Data is often more verbose and error-prone than straight code.
But there is a sweet spot where data is vastly superior. In those cases, it makes your code more readable. It is more amenable to analysis. It can be passed over the wire. When I find one of those cases, you bet I'll prefer data over functions.
I think that doing data-driven programming is one of the things Clojure excels at, even more than other Lisps, because of its literal data structure syntax. Data-driven programming is one of the deep experiences that I wish everyone could have. And it's the primary goal of LispCast Introduction to Clojure, my 1.5 hour video course filled with visuals, animations, exercises, and screencasts. Check out the preview.
You might also like
September 17, 2014
Summary: ClojureScript adds a lot of value on top of the Javascript platform. But some of that value can be had directly in Javascript without using a new language.
ClojureScript is a dialect of Clojure that compiles to Javascript. It lets you run Clojure in a browser or on Node. Just like Clojure, it has immutable data structures, literals for those data structures, macros, and core.async support.
These features are very powerful and they give ClojureScript a lot of power above Javascript. But a lot of that power can be had in Javascript through libraries, tools, and now some ES6 features. If you can't make the switch to ClojureScript, these tools might help you out. If you've heard of all the cool stuff that ClojureScript can do, well, this might be a good way to dip your toes in before you jump in.
David Nolen, the maintainer of ClojureScript, has wrapped up the ClojureScript immutable data structures to be used as a Javascript library which he calls mori. He's put in a lot of work to make it convenient to use from Javascript. It's not just the datastructures. It also has all of the functional goodness that makes them powerful to use.
CSP stands for Communicating Sequential Processes. It's a model of concurrency that is used in Go and in Clojure core.async. It's a powerful tool, especially in Javascript, where you don't have threads. Once you use it, you'll never go back.
Well, thanks to Generators in EcmaScript 6, you can write CSP code in Javascript. There's a library called js-csp that does just that.
JSON is a great format for data exchange, but it has limitations. One of the biggest limitations is that it is not extensible. You cannot define new types. Wouldn't it be nice to have values that get parsed as Javascript Date objects? Another limitation is that map keys can only be strings.
The edn format is Clojure's literal syntax made into a data format. It includes many data structures, including symbols, keywords, sets, maps, lists, and vectors. It is also extensible with tagged literals, meaning a small tag can be placed in front of a value to indicate the semantic meaning of that value. There are a couple of built-in tags, such as #instant for Dates and #uuid for, yes, UUIDs. But the important thing is you can define your own and define how they get parsed.
There's a Javascript library for parsing and generating edn.
edn is a great format, but parsing it in Javascript is never going to be as fast as parsing JSON. The JSON parser is written in C and highly optimized. Because of that limitation, the folks who build Clojure wrote Transit, which is a data format that serializes to JSON. It's semantically equivalent to edn, so it's extensible, but it's also JSON, so it's fast to parse. There's a Javascript implementation.
Macros are one of those legendary things Lisps are known for. They let you write code that writes code. Well, that's kind of a meaningless statement. Think of it more like extensible syntax. You can write a new type of syntax which will be translated to plain Javascript.
There's a macro system for Javascript called Sweet.js. The macro system is similar to the one found in Scheme systems. This isn't directly from Clojure, but you get the same power. Macros are a great way to extend a language. You no longer have to wait for a new language feature to be implemented. You can do it yourself.
Conclusion
The Javascript community is active and growing. There are plenty of smart people making cool libraries that can revolutionize your programs. One of Clojure's philosophies is to have a small core language and extend, to the extent possible, using libraries. So, those libraries can often be leveraged outside of Clojure, which is true in the case of mori. Or they are simply standardized to work cross-platform, like edn and Transit. CSP and macros are simply powerful tools that can be added to many languages.
Go give these tools a try. If you like them, you might like Clojure/ClojureScript. They will be here when you're ready. And when you are ready, I must recommend LispCast Introduction to Clojure. It's a video course designed and produced to take you from zero to Clojure.
You might also like
January 13, 2014
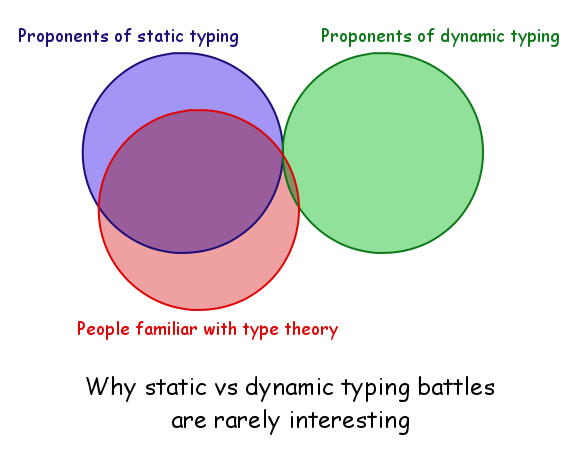
All sarcasm aside, the above diagram has a kernel of truth. The important thing to note is that the intersection between "Proponents of dynamic typing" and "People familiar with type theory" is very small.
In an effort to increase the size of that intersection, I decided to familiarize myself with a little more type theory. I developed an implementation of Hindley-Milner which operates on a simple Lisp-like λ-calculus with let polymorphism. Everything you need for Hindley-Milner Algorithm W.
Background
Hindley-Milner is a type system that is used by ML and Haskell. Algorithm W is a fast algorithm for inferencing Hindley-Milner which is syntax-directed (meaning it is based on the type of expression) and recursively defined. In this way, it is similar to Lisp's eval.
Implementation
I based my implementation on a paper called Algorithm W Step by Step which implemented it in Haskell. My implementation started very similar to that implementation and diverged as I refactored it into a more Clojure-esque style.
This implementation uses no in-place mutation, instead using a "substitution style" which is slightly harder to read. It is, however, easier to write and prove correct.
In addition to the type inferencer, I wrote an interpreter for the same language, just because. My original intent was to expose (to myself) the similarities between syntax-driven type inference and eval. There might be some, but the full clarity I desire is yet many refactorings away. Note that the interpreter and type inferencer are completely independent, except that both apply to the same set of expressions.
I added a couple of minor luxuries to the language having to do with currying. Writing fully parentheisized function applications for curried functions is a pain, as is writing a hand-curried function with multiple arguments. I added two syntax transformations which transform them into a more Lispy style. For example:
(fn [a b c d e f] 1) => (fn a (fn b (fn c (fn d (fn e (fn f 1))))))
and
(+ 1 2) => ((+ 1) 2)
I'm pretty sure the syntactic transformation is completely safe. All of my tests still type check.
The final luxury is that it is a lazily-evaluated language. That's not strictly necessary, but it is strictly cool. It builds up thunks (Clojure delays and promises) and a trampoline is used to get the values out. This lets me define if as a function. The only special forms are let and fn.
Where to find it
You can find the code in the ericnormand/hindley-milner Github repo. I don't promise that it has no bugs. But it does have a small and growing test suite. Pull requests are welcome and I will continue to expand and refactor it.
What I learned
Type unification is why the error messages of most type inferencers are so bad. Unification by default only has local knowledge and is commutative (unify a b == unify b a). No preference is given to either argument. A lot of work must have gone into making the error messages of Haskell as good as they are.
Let polymorphism is useful and I'm glad that Haskell has it.
Hindley-Milner is powerful, but it does not by itself work magic on a languageq. A language still requires a lot of good design and a well-chosen set of types.
Your turn
I think you should implement Hindley-Milner in the language of your choice for a small toy λ-calculus. There is a lot to learn from it, even if you never program using a Hindley-Milner language. At the very least, you'll know what the fuss is about.
If you think it would be helpful, have a look at my implementation. Like I said, pull requests are welcome.
For more inspiration, history, interviews, and trends of interest to Clojure programmers, get the free Clojure Gazette.
Learn More
Clojure pulls in ideas from many different languages and paradigms, and also from the broader world, including music and philosophy. The Clojure Gazette shares that vision and weaves a rich tapestry of ideas from the daily flow of library releases to the deep historical roots of computer science.
You might also like
December 03, 2013
Heroku is a great service, especially for the lone developer who wants free hosting for an app. The free hosting works just like the paid service except that your server will be "spun down", meaning that after five minutes of no activity, your server is stopped. It will be "spun up" again when there is a request. This spin up process can take a while and certainly does not give a good user experience.
Luckily there is a recommended way of avoiding this delay. The solution is to run New Relic monitoring, which periodically polls your server, avoiding the five minutes of no activity and hence keeping your server running.
In addition to keeping your server from falling asleep, it also gathers lots of profiling information that could help you understand your server as it runs in production. Luckily, both Heroku and New Relic offer free tiers. This brings us to my favorite financial formula:
Free + Free = Free
You can also use this process with the paid versions. Note also that Heroku itself recommends setting this up, so don't feel guilty!
Instructions
I am assuming you are already using Heroku and have a working app hosted there, using an uberjar deploy. You also have the Heroku Toolbelt installed.
1. Add the New Relic add-on to your app.
$ heroku addons:add newrelic:stark
I recommend the stark plan for free apps. You can choose any of the New Relic tiers.
2. Find and download the latest New Relic Java API release.
This download page lists all of the versions. Find the latest one and download the ZIP file.
3. Unzip the ZIP file into the base of your app.
$ cd projects/my-app
$ unzip ~/Downloads/newrelic-java-3.2.0.zip
It should unzip into a newrelic/ directory.
4. Check your .gitignore file for *.jar
New Relic includes its own JAR file which needs to be deployed with your app in the git repo. My .gitignore included a line *.jar which would exclude all JAR files. Remove this line if you see it.
5. Add the .gitignore and the newrelic/ directory to your repo.
$ git add .gitignore
$ git add newrelic
$ git commit -m "Add New Relic monitoring agent."
Make sure the file newrelic/newrelic.jar was added.
6. Release to Heroku.
$ git push heroku master
We need to add a new JVM option. There is an environment variable called JVM_OPTS which is typically used to do this. Find out what value it has now.
$ heroku config
Find the line starting with JVM_OPTS:. Mine says "-Xmx400m". Now we add this to the variable: "-javaagent:newrelic/newrelic.jar".
$ heroku config:set JVM_OPTS="-Xmx400m -javaagent:newrelic/newrelic.jar"
The app should restart with the new options. Visit your Heroku dashboard, find your app, and click on the New Relic addon to see the New Relic Dashboard for your app. The first load might take some time, but subsequent loads will be at full speed and it won't spin down. load!
References:
You might also like
August 06, 2014
Summary: Clojure core.async is a way to manage mutable state. Isn't that against functional programming?
When core.async was first announced, there was a lot of fanfare. But among the celebration, there was some consternation about core.async. Isn't core.async against the functional principles of Clojure? Aren't channels just mutable state? Aren't the <! and >! operations mutation?
Well, it's true. core.async is about mutation. It's procedural code. Go blocks run their bodies one step at a time. It's imperative.
But that's what Clojure is all about. It makes functional programming easy (with fns, immutable data structures, and higher order functions). It also makes mutable state easy to reason about. It does not eliminate it. It simply gives you better abstractions. That's what Atoms, Refs, Vars, and Agents are: useful abstractions for dealing with state.
core.async is just another abstraction for dealing with state. But, following the Clojure philosophy, it was chosen to be easy to reason about. The hardest part about coordinating and communicating with independent threads normally is that neither of them know what the other is doing. You can make little signals using shared memory. But those signals get complicated fast once you scale past two threads.
And that's what a channel is: it's just a shared coordination point. But it has some cool properties that make it super easy to reason about:
- Carry semantics: the channel carries its own coordination semantics (buffering, unbuffered, etc).
- Simple interface: channels have put, take, and close. That's it.
- Very scalable: any number of processes can use a single channel with no additional cost.
- Decoupling: consumers don't need to know producers and vice versa.
Channels are awesome, but they're not the whole story. The other part of core.async is the go block. Go blocks are another abstraction. They allow you to write code in an imperative style that blocks on channels. You get to use loops and conditionals, as well as local let variables, global variables, and function calls -- everything you're already using, but augmented with the coordination power of channels.
All of these features add up to something you can reason about locally. That's the key: the code you're looking at now can be understood without looking at other code.
But there's a downside: you now have more choices. In theory, they're easier choices. But that requires you to understand the choices. You need to understand the abstractions, the idioms, and the tradeoffs. That's the goal of the LispCast Clojure core.async video course. If you'd like to use core.async but you don't know where to start, this is a good place.
You might also like
July 10, 2014
Summary: Clojure is well-suited for processing JSON, but there are some decisions you have to make to suit your application. The major decisions are actually easy, though they took me a while to figure out.
I tend to use JSON instead of edn for an API serialization format, if only because JSON is more readily readable from other languages. I could do both, but it's good to eat your own dogfood and test those JSON code paths.
edn is better, but JSON is generally pretty good. However, JSON's expressibility is decidedly a subset of the Clojure data structures, so there is considerable loss of information when going from Clojure to JSON. That information is not recovered in a round-trip, at least not automatically. There are lots of decisions that have to go into how to, at least partially, recover this.
One bit of information that is lost is the type of keys to a map. JSON only allows strings as keys. Clojure allows anything. But most of the time, I find myself using keywords for keys. I say most, but really, it's the vast majority. Maps are bundles of named values pretty much all the time. So the optimal decision, after trying lots of combinations, is to convert keywords to strings (the default in JSON libraries I've seen) when emitting JSON; and to convert map keys (always strings in JSON) to keywords (also known as keywordize-keys) when parsing JSON. That covers nearly all cases, and pinpointed special cases can cover the rest.
But that's not the end of the keyword/string story. What about namespaces? Surprisingly, the two major JSON libraries, clojure.data.json and cheshire handle things differently. How do you parse a JSON key that has a slash in it, indicating a namespace? If we're keywordizing (as I suggest above), they both give namespaced keywords (keyword will parse around the /). But when emitting JSON, they act differently. clojure.data.json will emit the name of the keyword (and ignore the namespace) while cheshire emits a string with "namespace/name".
I like to keep the namespace, or, put another way, I like to drop as little information as possible. So I prefer the namespace approach. I'm not sure how to get clojure.data.json to do that. I just use cheshire. The other gotcha for namespaces is that ClojureScript's clj->js and js->clj are similarly asymetrical.
Keywords in other places besides the keys of maps will just get turned into strings, but they don't get converted back to keywords. That sucks, but it's minor. You'll just have to convert them back some other way. At work, we use Prismatic Schema's coercions. They do the trick nicely, in a declarative way.
So, back to other JSON issues. The other issue is other data types. Dates, URI's, and UUID's are in our data as well. Dates, well, it's up to you how to encode them. I've always been a fan of the Unix timestamp. It's not exactly human readable, but it's universally parseable. There's also the ISO datetime format, which is probably a better bet--it's human readable and agreed upon among API designers. You could emit that as a string and coerce back to a Date object later.
URI's and UUID's are by definition strings, so that's easy. How do you set up cheshire to handle the encoders? It's pretty simple, really.
(cheshire.generate/add-encoder java.net.URI cheshire.generate/encode-str)
That means add the encoder for the java.net.URI type to be encoded as a JSON string. str will be called on the value. You can figure out the other types you need. There are some JSON emission settings built-in, including Date (the ISO string format) and UUID. Weirdly URI is not in there, so you have to add it.
What's next? Oh, pretty-printing. Yeah, I pretty-print my JSON to go over the wire. It's nice for debugging. I mean, who wants to curl one long, 1000-character line of JSON? Put some whitespace, please! How to do that?
(cheshire.core/generate-string mp {:pretty true})
That's right, it's basically built in, but you have to specify it. But, oh man, that's long. I don't want to type that, especially because my lazy fingers are going to not do it one time, then I'm going to look at the JSON in my browser and see a one-line JSON mess. So, what do I do? I put all my JSON stuff for each project in json.clj. It's got all my add-encoder stuff, and it's got two extra functions, just for laziness:
(defn parse [s]
(cheshire.core/parse-string s true))
(defn gen [o]
(cheshire.core/generate-string o {:pretty true}))
Or of course whatever options you want to pass those functions. This one is my choice--you make your choice. But these two functions are all I use most of the time. Parsing strings and generating strings. Woohoo! Much shorter and less to keep in my little head.
Well, that just about wraps up my JSON API story. There's the slight detail of outputting JSON from liberator, which is its own blog post. And there's a bit of generative testing I do to really challenge my assumptions about how I set up the round-tripping. But that, too, is another blog post for another day. Oh, and what about all that JSON middleware? Again, another post.
If you like peanut butter and you like jelly, you will probably like peanut butter and jelly sandwiches. If you like web and you like Clojure, you will most definitely like Web Development in Clojure, which is a gentle, soothing, visually rich video course ushering in the fundamentals of Clojure web development through your eyes and ears and down through your fingertips and into your very own Heroku-hosted web server. At least watch the preview!
You might also like
May 27, 2014
Summary: Lists are kind of warty in Clojure. Care should be taken, especially by those coming from other Lisps.
One of the things that still trips me up in Clojure is the actual types of lists. I used to program in Common Lisp, where things are a bit easier to understand: something is either a list or an atom. Lists are built out of conses and end with nil. Everything else is an atom.
Coming from Common Lisp, one might expect this to work:
=> (listp (cons 1 nil))
In CL, it will be true. In Clojure, it is also true. (Try it out yourself!) Launch a REPL. Go to Try Clojure.
=> (list? (cons 1 nil))
What about this:
=> (list? (cons 1 (cons 1 nil)))
We're consing onto a list, should be a list, no?
In Common Lisp, yes. In Clojure?
NO!
That's not a list. Go ahead, try it at your Clojure REPL.
What gives? How is that possible? Are we living in a Kafkaesque ECMAScript World?
Well . . . probably.
What's going on? Put on your Indiana Jones fedora. We're going on an adventure deep into the heart of the Clojure JVM implementation.
First, how is list? defined?
In clojure.core:
(defn list?
"Returns true if x implements IPersistentList"
{:added "1.0"}
[x] (instance? clojure.lang.IPersistentList x))
Great, list? is just an instance check. What classes implement clojure.lang.IPersistentList? According to the javadoc on the Clojure sources, there are two: PersistentQueue and PersistentList. There's also a static inner class in PersistentList called EmptyList.
Let's see those at the REPL:
=> (type ())
clojure.lang.PersistentList$EmptyList
=> (list? ())
true
=> (type (list 1 2 3))
clojure.lang.PersistentList
=> (list? (list 1 2 3))
true
=> (type clojure.lang.PersistentQueue/EMPTY)
clojure.lang.PersistentQueue
=> (list? clojure.lang.PersistentQueue/EMPTY)
true
These all return true when given to list?. What about (cons 1 nil)?
=> (type (cons 1 nil))
clojure.lang.PersistentList
=> (list? (cons 1 nil))
true
Great. Consing onto nil gives you a list. Let's cons onto a list:
=> (type (cons 0 (list 1 2 3)))
clojure.lang.Cons
=> (list? (cons 0 (list 1 2 3)))
false
Oh, no! Why does consing onto nil create a list, but consing onto a list create a cons? Poisonous dart averted! Back to the source code!
In clojure.core:
(def
^{:arglists '([x seq])
:doc "Returns a new seq where x is the first element and seq is
the rest."
:added "1.0"}
cons (fn* cons [x seq] (. clojure.lang.RT (cons x seq))))
So it calls clojure.lang.RT/cons. We can look that up:
static public ISeq cons(Object x, Object coll){
//ISeq y = seq(coll);
if(coll == null)
return new PersistentList(x);
else if(coll instanceof ISeq)
return new Cons(x, (ISeq) coll);
else
return new Cons(x, seq(coll));
}
Wow! The code is clear: if the second argument is null (nil), it makes a PersistentList. Otherwise, it constructs a clojure.lang.Cons, which is not a list! We're at the root of our wart, but there's nothing we can really do about it except keep exploring.
If I have a list (according to list?) and I want to add an element to the front to make a new list, how do I do that?
Well, the answer is a little disappointing:
=> (def ls (list 1 2 3))
=> (def ls2 (conj ls 0))
=> (list? ls2)
true
conj will maintain the type, cons will not. What happens if I conj onto a Cons?
=> (def c (cons 1 (cons 2 nil)))
=> (conj c 0)
(0 1 2)
=> (type (conj c 0))
clojure.lang.Cons
So, there you have it. It's a bit of a wart having all of these slightly different types and predicates like list? that slice them up in odd ways. Sometimes it's like running away from a giant paper-mache ball.
In Clojure's defense, I will say that I rarely use list?, if at all. It's not a very useful function in clojure.core. I'm usually working at a much higher level than that, thinking in terms of sequences (an abstraction), not their concrete implementations. And in the end, you never get out of danger.
There you have it. If you'd like to learn more Clojure, I have a nice video series:
You might also like










